Execute Terraform Commands on Multiple Modules at Once

Execute Terraform commands on multiple modules at once
Motivation
Let’s say your infrastructure is defined across multiple Terraform modules:
root
├── backend-app
│ └── main.tf
├── frontend-app
│ └── main.tf
├── mysql
│ └── main.tf
├── redis
│ └── main.tf
└── vpc
└── main.tf
There is one module to deploy a frontend-app, another to deploy a backend-app, another for the MySQL database, and so on. To deploy such an environment, you’d have to manually run terraform apply in each of the subfolder, wait for it to complete, and then run terraform apply in the next subfolder. How do you avoid this tedious and time-consuming process?
The run-all command
To be able to deploy multiple Terraform modules in a single command, add a terragrunt.hcl file to each module:
root
├── backend-app
│ ├── main.tf
│ └── terragrunt.hcl
├── frontend-app
│ ├── main.tf
│ └── terragrunt.hcl
├── mysql
│ ├── main.tf
│ └── terragrunt.hcl
├── redis
│ ├── main.tf
│ └── terragrunt.hcl
└── vpc
├── main.tf
└── terragrunt.hcl
Now you can go into the root folder and deploy all the modules within it by using the run-all command with apply:
cd root
terragrunt run-all apply
When you run this command, Terragrunt will recursively look through all the subfolders of the current working directory, find all folders with a terragrunt.hcl file, and run terragrunt apply in each of those folders concurrently.
Similarly, to undeploy all the Terraform modules, you can use the run-all command with destroy:
cd root
terragrunt run-all destroy
To see the currently applied outputs of all of the subfolders, you can use the run-all command with output:
cd root
terragrunt run-all output
Finally, if you make some changes to your project, you could evaluate the impact by using run-all command with plan:
Note: It is important to realize that you could get errors running run-all plan if you have dependencies between your projects and some of those dependencies haven’t been applied yet.
Ex: If module A depends on module B and module B hasn’t been applied yet, then run-all plan will show the plan for B, but exit with an error when trying to show the plan for A.
cd root
terragrunt run-all plan
If your modules have dependencies between them—for example, you can’t deploy the backend-app until MySQL and redis are deployed—you’ll need to express those dependencies in your Terragrunt configuration as explained in the next section.
Additional note: If your modules have dependencies between them, and you run a terragrunt run-all destroy command, Terragrunt will destroy all the modules under the current working directory, as well as each of the module dependencies (that is, modules you depend on via dependencies and dependency blocks)! If you wish to use exclude dependencies from being destroyed, add the --terragrunt-ignore-external-dependencies flag, or use the --terragrunt-exclude-dir once for each directory you wish to exclude.
Passing outputs between modules
Consider the following file structure:
root
├── backend-app
│ ├── main.tf
│ └── terragrunt.hcl
├── mysql
│ ├── main.tf
│ └── terragrunt.hcl
├── redis
│ ├── main.tf
│ └── terragrunt.hcl
└── vpc
├── main.tf
└── terragrunt.hcl
Suppose that you wanted to pass in the VPC ID of the VPC that is created from the vpc module in the folder structure above to the mysql module as an input variable. Or if you wanted to pass in the subnet IDs of the private subnet that is allocated as part of the vpc module.
You can use the dependency block to extract the output variables to access another module’s output variables in the terragrunt inputs attribute.
For example, suppose the vpc module outputs the ID under the name vpc_id. To access that output, you would specify in mysql/terragrunt.hcl:
dependency "vpc" {
config_path = "../vpc"
}
inputs = {
vpc_id = dependency.vpc.outputs.vpc_id
}
When you apply this module, the output will be read from the vpc module and passed in as an input to the mysql module right before calling terraform apply.
You can also specify multiple dependency blocks to access multiple different module output variables. For example, in the above folder structure, you might want to reference the domain output of the redis and mysql modules for use as inputs in the backend-app module. To access those outputs, you would specify in backend-app/terragrunt.hcl:
dependency "mysql" {
config_path = "../mysql"
}
dependency "redis" {
config_path = "../redis"
}
inputs = {
mysql_url = dependency.mysql.outputs.domain
redis_url = dependency.redis.outputs.domain
}
Note that each dependency is automatically considered a dependency in Terragrunt. This means that when you run run-all apply on a config that has dependency blocks, Terragrunt will not attempt to deploy the config until all the modules referenced in dependency blocks have been applied. So for the above example, the order for the run-all apply command would be:
- Deploy the VPC
- Deploy MySQL and Redis in parallel
- Deploy the backend-app
If any of the modules failed to deploy, then Terragrunt will not attempt to deploy the modules that depend on them.
Note: Not all blocks are able to access outputs passed by dependency blocks. See the section on Configuration parsing order for more information.
Unapplied dependency and mock outputs
Terragrunt will return an error indicating the dependency hasn’t been applied yet if the terraform module managed by the terragrunt config referenced in a dependency block has not been applied yet. This is because you cannot actually fetch outputs out of an unapplied Terraform module, even if there are no resources being created in the module.
This is most problematic when running commands that do not modify state (e.g run-all plan and run-all validate) on a completely new setup where no infrastructure has been deployed. You won’t be able to plan or validate a module if you can’t determine the inputs. If the module depends on the outputs of another module that hasn’t been applied yet, you won’t be able to compute the inputs unless the dependencies are all applied. However, in real life usage, you would want to run run-all validate or run-all plan on a completely new set of infrastructure.
To address this, you can provide mock outputs to use when a module hasn’t been applied yet. This is configured using the mock_outputs attribute on the dependency block and it corresponds to a map that will be injected in place of the actual dependency outputs if the target config hasn’t been applied yet.
For example, in the previous example with a mysql module and vpc module, suppose you wanted to place in a temporary, dummy value for the vpc_id during a run-all validate for the mysql module. You can specify in mysql/terragrunt.hcl:
dependency "vpc" {
config_path = "../vpc"
mock_outputs = {
vpc_id = "temporary-dummy-id"
}
}
inputs = {
vpc_id = dependency.vpc.outputs.vpc_id
}
You can now run validate on this config before the vpc module is applied because Terragrunt will use the map {vpc_id = "temporary-dummy-id"} as the outputs attribute on the dependency instead of erroring out.
What if you wanted to restrict this behavior to only the validate command? For example, you might not want to use the defaults for a plan operation because the plan doesn’t give you any indication of what is actually going to be created.
You can use the mock_outputs_allowed_terraform_commands attribute to indicate that the mock_outputs should only be used when running those Terraform commands. So to restrict the mock_outputs to only when validate is being run, you can modify the above terragrunt.hcl file to:
dependency "vpc" {
config_path = "../vpc"
mock_outputs = {
vpc_id = "temporary-dummy-id"
}
mock_outputs_allowed_terraform_commands = ["validate"]
}
inputs = {
vpc_id = dependency.vpc.outputs.vpc_id
}
Note that indicating validate means that the mock_outputs will be used either with validate or with run-all validate.
You can also use skip_outputs on the dependency block to specify the dependency without pulling in the outputs:
dependency "vpc" {
config_path = "../vpc"
skip_outputs = true
}
When skip_outputs is used with mock_outputs, mocked outputs will be returned without pulling in the outputs from remote states. This can be useful when you disable the backend initialization (remote_state.disable_init) in CI for example.
dependency "vpc" {
config_path = "../vpc"
mock_outputs = {
vpc_id = "temporary-dummy-id"
}
skip_outputs = true
}
You can also use mock_outputs_merge_strategy_with_state on the dependency block to merge the mocked outputs and the state outputs :
dependency "vpc" {
config_path = "../vpc"
mock_outputs = {
vpc_id = "temporary-dummy-id"
new_output = "temporary-dummy-value"
}
mock_outputs_merge_strategy_with_state = "shallow"
}
If the state outputs only contains vpc_id, this value will be preserved. And new_output which is not existing, the mock value will be used.
Dependencies between modules
You can also specify dependencies explicitly. Consider the following file structure:
root
├── backend-app
│ ├── main.tf
│ └── terragrunt.hcl
├── frontend-app
│ ├── main.tf
│ └── terragrunt.hcl
├── mysql
│ ├── main.tf
│ └── terragrunt.hcl
├── redis
│ ├── main.tf
│ └── terragrunt.hcl
└── vpc
├── main.tf
└── terragrunt.hcl
Let’s assume you have the following dependencies between Terraform modules:
backend-appdepends onmysql,redis, andvpcfrontend-appdepends onbackend-appandvpcmysqldepends onvpcredisdepends onvpcvpchas no dependencies
You can express these dependencies in your terragrunt.hcl config files using a dependencies block. For example, in backend-app/terragrunt.hcl you would specify:
Similarly, in frontend-app/terragrunt.hcl, you would specify:
Once you’ve specified the dependencies in each terragrunt.hcl file, when you run the terragrunt run-all apply or terragrunt run-all destroy, Terragrunt will ensure that the dependencies are applied or destroyed, respectively, in the correct order. For the example at the start of this section, the order for the run-all apply command would be:
- Deploy the VPC
- Deploy MySQL and Redis in parallel
- Deploy the backend-app
- Deploy the frontend-app
If any of the modules fail to deploy, then Terragrunt will not attempt to deploy the modules that depend on them. Once you’ve fixed the error, it’s usually safe to re-run the run-all apply or run-all destroy command again, since it’ll be a no-op for the modules that already deployed successfully, and should only affect the ones that had an error the last time around.
To check all of your dependencies and validate the code in them, you can use the run-all validate command.
To check the dependency graph you can use the graph-dependencies command (similar to the terraform graph command), the graph is output in DOT format The typical program that can read this format is GraphViz, but many web services are also available to read this format.
terragrunt graph-dependencies | dot -Tsvg > graph.svg
In the example above it’ll generate this graph
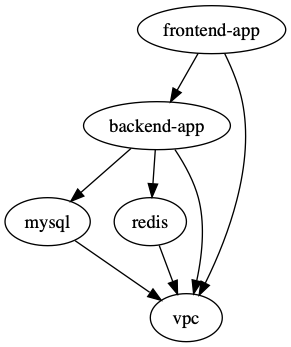
Note that this graph shows the dependency relationship in the direction of the arrow (top down), however terragrunt will run the action in reverse order (bottom up)
Note: During execution of destroy command, Terragrunt will try to find all dependent modules and show a confirmation prompt with a list of all detected dependencies, because once resources will be destroyed, any commands on dependent modules will fail with missing dependencies. For example, if destroy was called on the redis module, you will be asked to confirm the action because backend-app depends on redis. You can avoid the prompt by using --terragrunt-non-interactive.
Testing multiple modules locally
If you are using Terragrunt to configure remote Terraform configurations and all of your modules have the source parameter set to a Git URL, but you want to test with a local checkout of the code, you can use the --terragrunt-source parameter:
cd root
terragrunt run-all plan --terragrunt-source /source/modules
If you set the --terragrunt-source parameter, the run-all commands will assume that parameter is pointing to a folder on your local file system that has a local checkout of all of your Terraform modules. For each module that is being processed via a run-all command, Terragrunt will read in the source parameter in that module’s terragrunt.hcl file, parse out the path (the portion after the double-slash), and append the path to the --terragrunt-source parameter to create the final local path for that module.
For example, consider the following terragrunt.hcl file:
terraform {
source = "git::git@github.com:acme/infrastructure-modules.git//networking/vpc?ref=v0.0.1"
}
If you run terragrunt run-all apply --terragrunt-source /source/infrastructure-modules, then the local path Terragrunt will compute for the module above will be /source/infrastructure-modules//networking/vpc.
Limiting the module execution parallelism
By default Terragrunt will not impose a limit on the number of modules it executes when it traverses the dependency graph, meaning that if it finds 5 modules it’ll run terraform 5 times in parallel once in each module. Sometimes this might create a problem if there are a lot of modules in the dependency graph like hitting a rate limit on some cloud provider.
To limit the maximum number of module executions at any given time use the --terragrunt-parallelism [number] flag
terragrunt run-all apply --terragrunt-parallelism 4